
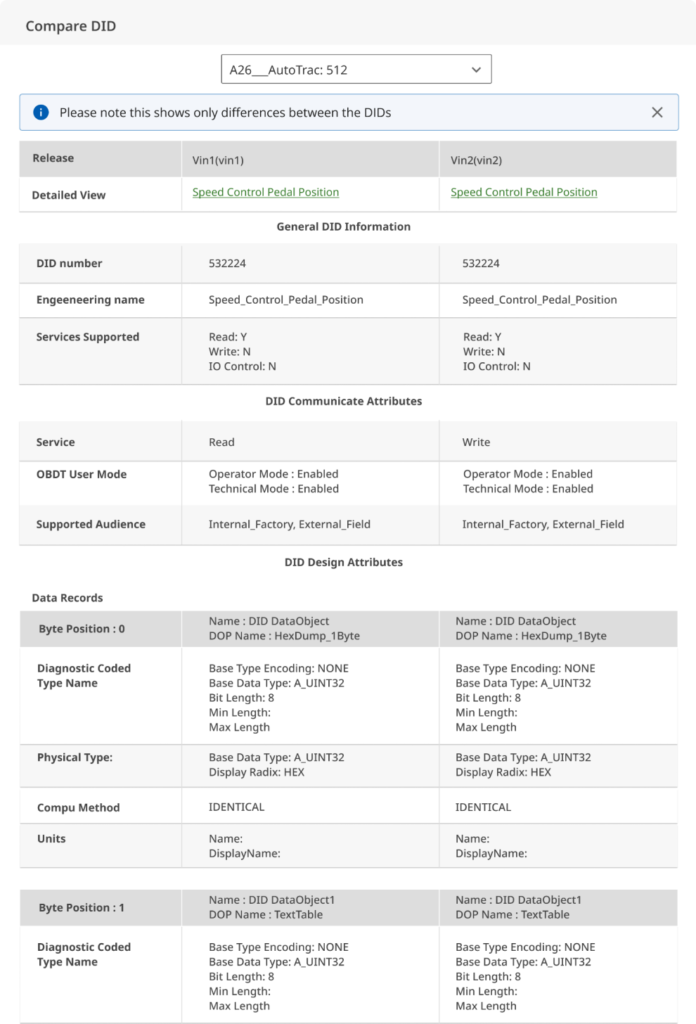
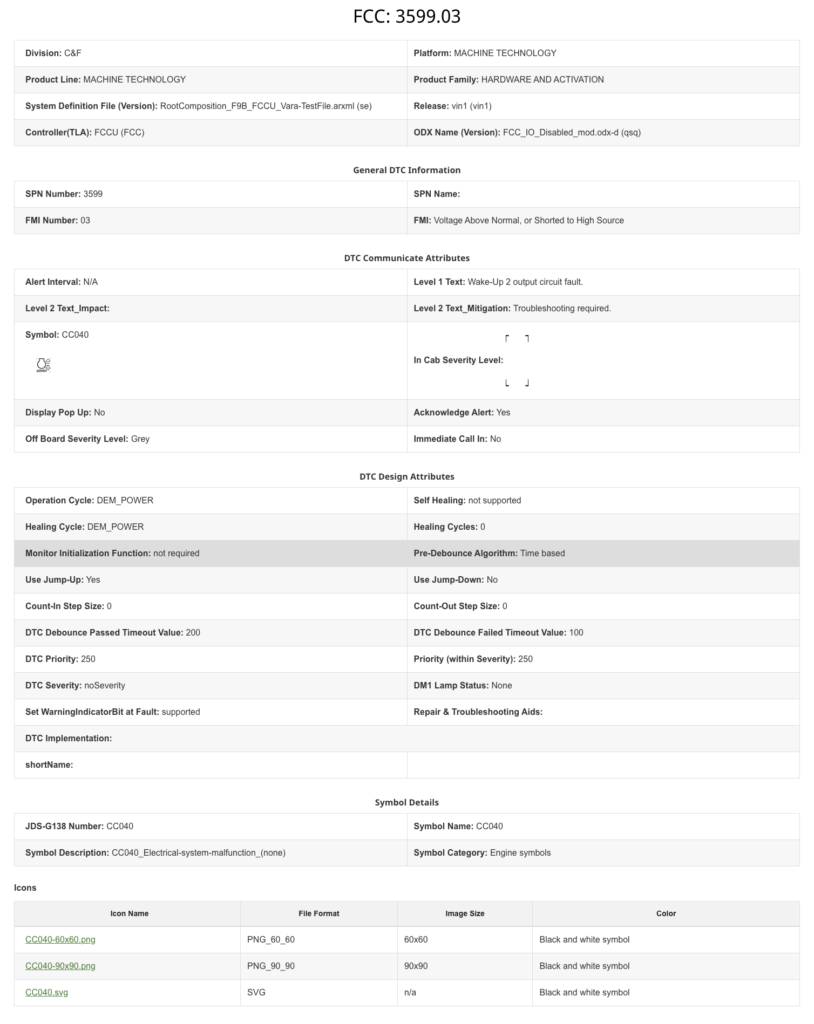
When comparing the 2 files having 10,000s of variables, and multi level drill down (3 in the specific case) it becomes crucial to keep the data simple and still covering all the details necessery. We reduced the Drill Down to single level and introduced selective loading to reduce the overall loading time for the user
This is a small section of large project.
The application is mainly focused on facilitating the autosar exchange with embeded systems for the vehicles manufactured and maintained by the business. It simplifies the data and convert it to the business used formats, add translations for the vehicles used in different countries as well as provides ability create the data points needed.
This is a complete redesign of the existing MVP created earlied. I was assigned to provide guidance and support to the teams mid way while development of redesigned product, which then turned into major project in the kitty.
Whenever a new System Defination file (SDF) is released for a application the engineers need to calibrate the devices according to the new release. since every SDF release has 10,000s of variables, the engineers(users) have difficulty in understanding the changes and they tend to calibrate the complete system again with the new SDF release. This not only takes up more time and resources but also keeps the engineer puzzled about what changes were done in the SDF release. So the aim in the case was comparing the 2 releases to understand the difference between them in easiest possible way.
This feature was much complex and would demand much more user research. Due to some specific needs of the stake holders we had to take up this feature on fastrack and was decided to take up research and and redesign in next few PSIs.
As the Data is far more technical and specific to the users, who are mostly engineers too we conducted a small workshop including the some representative of users, developers, testers(QAs) and product owners. This exercise was conducted to come to the some specfic ideas that will better design the comparision page to follow maximum usability principles.
The team came with with following pointers
1. To tackle the issue of.Computation time needed for comparison of this data and the complexity of the data, it was decided to only load the differences and ignore the similarities between the releases.
2. Since every release will have multiple controllers and each controller will have almost similar and a large amount of nested data, it was decided through the suggestion of some Developers that we should go ahead with loading data of individual controller at a time.
We decided to have the details for the individual drilldown for DIs in one modal that will compare the data of individual data identifiers (DTC, DID, RID)
3. All the further drill downs were decided to be flat and an included in this model itself So that will avoid the confusion that user might have while drilling down the comparison one by one.
So with the key stakeholders we conducted mini design sprints that lasts for 3-4 days with the stakeholders contributing few hours every way to the design sprint. Now this sprint helps in understanding the problem, getting to some specific solutions and validating those solutions with the key stakeholders, So hear some few some brief findings from the Mini Sprint.
The case was moer of a UI design challenge than a UX or usability challenge. We just had a stake holder demo and started execution which by the nature itself is a long task.
The user interviews to understand the exact process of calliberation, the stats around the changes and the detail protocol is being designed. The plan is to provid the data in a way thet they can use the comparision report in most effecient way reducing chances of error by contiously reducing the cognetive and memory load on the users.